Промпты и тесты
Копируйте точные инструкции для ИИ, которые я использовал в видео для каждого кейса.

Семь практических кейсов о том, где ИИ уже помогает в реальных задачах: выбор модели, OSINT, биомеханика, MVP, аналитика данных, аудит продукта и работа с большими отчетами.
Здесь собраны все промпты, конфигурации и результаты живых тестов из ролика. Используйте эти блоки как дополнение к видео.
Каждый кейс — это промпты, живые тесты и итоговые файлы. Держите страницу открытой рядом с видео и копируйте инструкции напрямую.
Копируйте точные инструкции для ИИ, которые я использовал в видео для каждого кейса.
Смотрите полную версию на YouTube для понимания логики процесса и моих рассуждений.
Скачивайте и изучайте финальные результаты: от логотипов до экспорта данных из CSV.
Если вы здесь впервые, начните с Кейса 1. Он задает логику всей серии, а дальше уже можно идти по порядку или открывать только нужный сценарий.
Открыто 7 кейсов
Сравнение четырех моделей на одной задаче: реальные ответы, официальный бенчмарк, скриншоты и экономика API.
OSINT-проверка на нейтральном кадре: как модель шаг за шагом выходит на точную локацию и чем это подтверждается.
Разбор тяги на реальном видео: ошибки техники, сбой компьютерного зрения и проверка результата уже на следующей тренировке.
Полный путь от слабой идеи к собранному MVP: критика гипотезы, визуалы, видео и промпты для запуска бренда.
Переход от CSV к рабочему аналитическому инструменту: сначала анализ в Python, потом интерфейс для команды.
Связка аудита и внедрения: сначала ИИ находит UX/UI-проблемы, затем эти замечания доходят до реальных правок в коде.
Работа с большими отчётами без простыни текста: структура, противоречия, аудиоразбор и готовая презентация по итогам.
Начинаем с базового, но очень показательного теста: какая модель не просто красиво рассуждает, а действительно понимает физический смысл задачи. Для автоматизаций и агентных сценариев это критично, потому что ошибка тут быстро превращается в реальные потери.
Выбирать модель лучше не по бренду, а по двум критериям: устойчивость логики и стоимость использования.
Для логики сложных бизнес-процессов в этой проверке лидируют Gemini и Claude 4.6. ChatGPT при этом остается полезным инструментом для бытовых задач и бюджетного кодинга, особенно когда нужен быстрый первый вариант решения.
Для построения рабочих бизнес-процессов и агентных сценариев способность модели корректно понимать физический смысл задачи — один из ключевых критериев. Ошибка автономного ИИ-агента может приводить к прямым финансовым потерям. Мы сравнили актуальные модели Google, OpenAI, Anthropic и DeepSeek, а в финале рассмотрели экономику API.
Автомойка в 100 метрах от моего дома. Как мне быстрее помыть машину — дойти пешком или доехать на машине эти 100 метров? Рассуждай шаг за шагом.
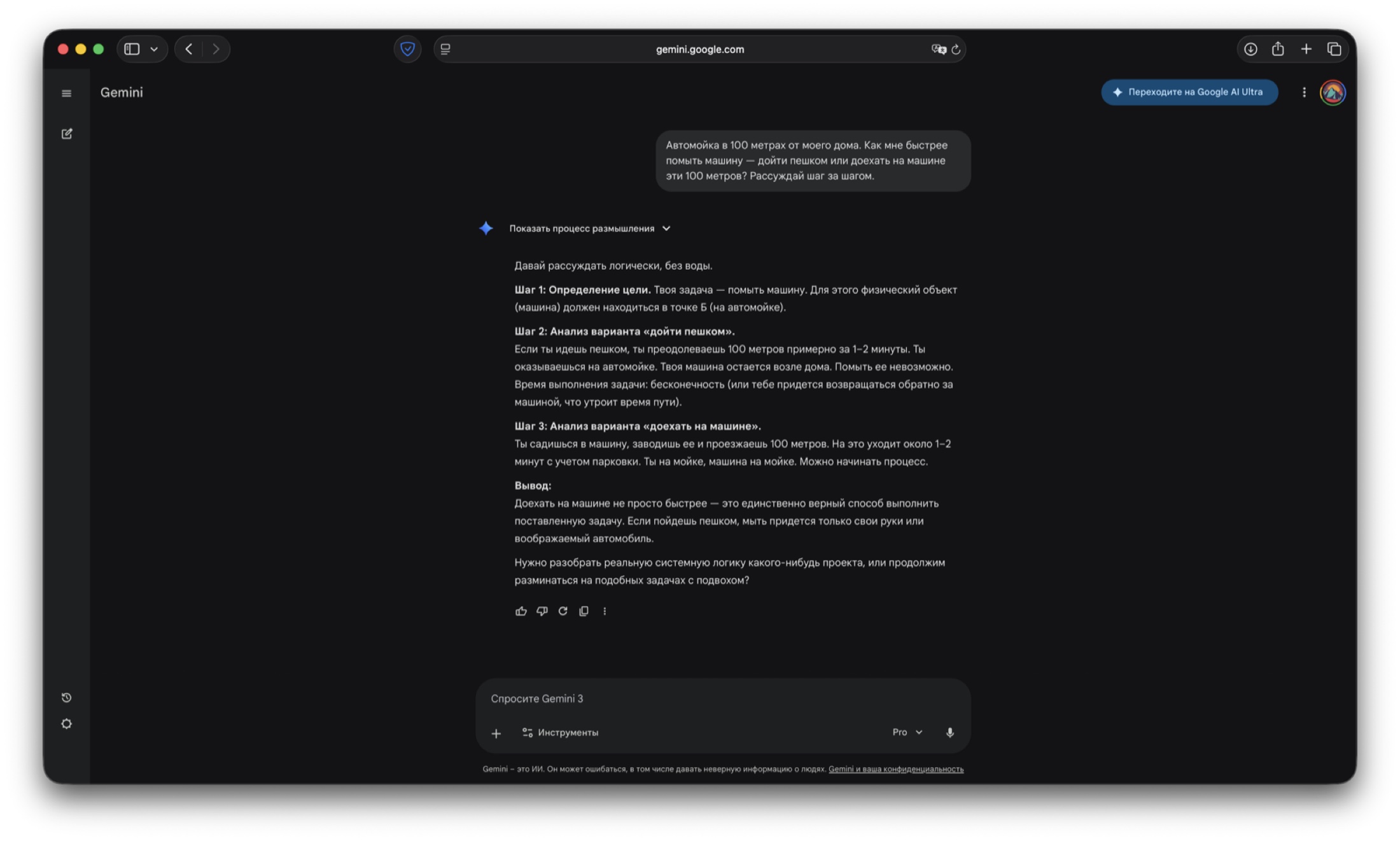
Модели от Google продемонстрировали наиболее глубокое понимание причинно-следственных связей реального мира.
Модель не просто измерила расстояние, а учла механику процесса. В ответе зафиксировано: «даже для 100 метров желательно, чтобы масло в ДВС немного разошлось». Алгоритм логично отверг пеший сценарий: пока вы идете на проверку и возвращаетесь за автомобилем, свободный бокс может занять другой клиент. Дополнительно нейросеть предложила агентский подход (удаленно проверить загрузку или позвонить) и корректно удержала контекст предыдущего диалога, включая тему экзамена по вождению.
Вердикт: Точное удержание контекста и физики задачи.
Решила задачу через строгую дедукцию: автомобиль — физический объект, который необходимо доставить в точку B. Вывод модели: если идти пешком, задача не выполняется, так как автомобиль остается у дома. В развернутом ответе модель добавила ироничную ремарку, что в пешем сценарии фактически остается «мыть только воображаемый автомобиль».
Вердикт: Логика без разрывов между текстом и реальным миром.
Ответ Gemini 3.1 Pro: модель сразу возвращает разговор к цели задачи и фиксирует, что пешком машину не помыть, потому что автомобиль останется у дома.
Проверка актуального модельного ряда ChatGPT, включая Thinking-режим, показала уязвимость к ложным логическим веткам.
Алгоритм корректно посчитал математику: 100 метров пешком — 1–2 минуты. Затем потерял физический смысл задачи и выдал ошибку контекста: «Если все готово, вы сразу можете начать мойку машины». Ключевая проблема в том, что модель не удержала обязательный факт: без автомобиля на автомойке действие невозможно.
Вердикт: Идеальная арифметика, но ошибка в базовой причинно-следственной цепочке.
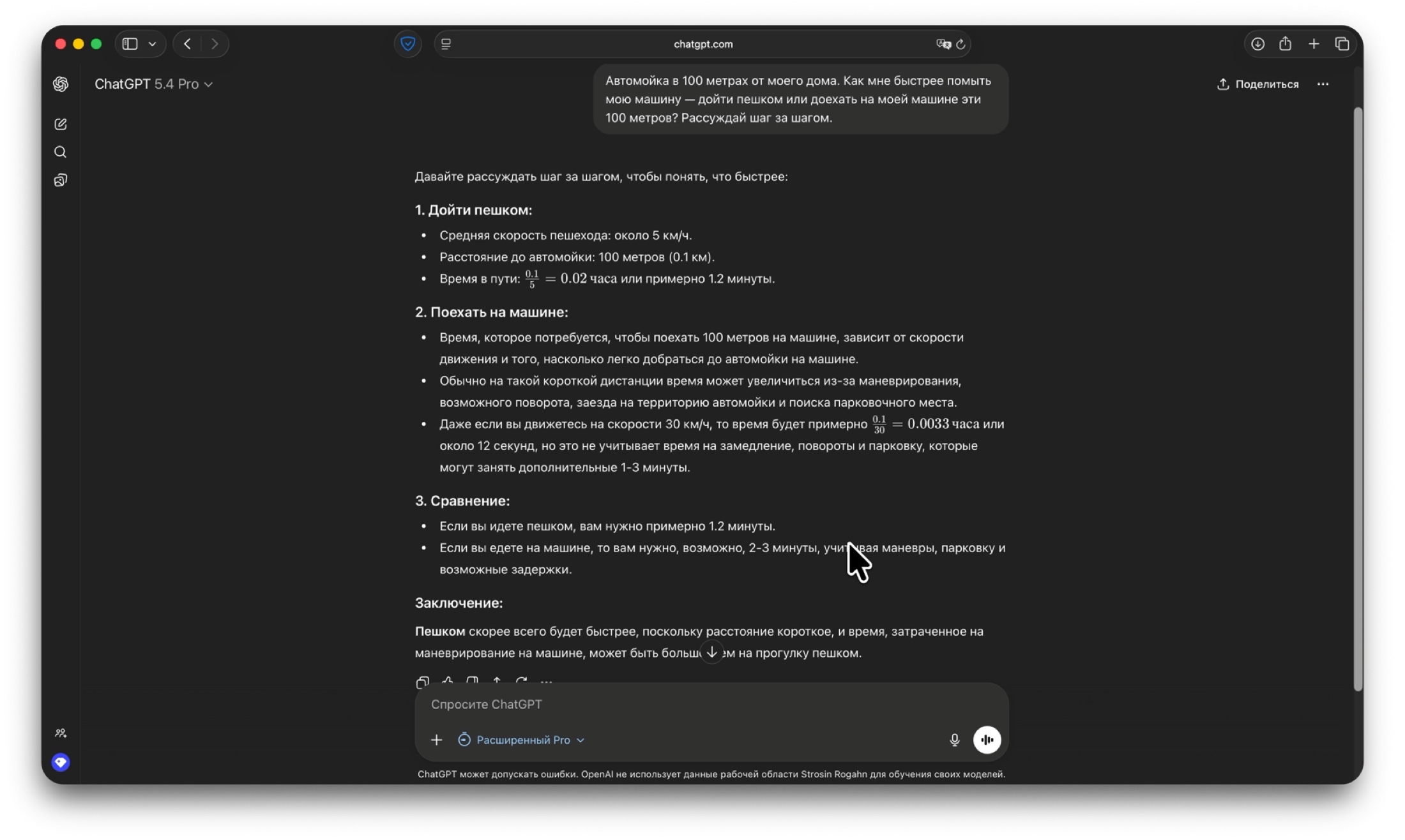
Я даже отдельно уточнил, что речь идет именно про мою машину, а не про какой-то абстрактный автомобиль. Для большинства людей это вообще не вопрос, потому что второй машины рядом просто нет. Несмотря на эту конкретизацию, модель снова ушла в подробные расчеты скорости пешехода, времени маневров и дробных интервалов, а финальный вывод остался тем же: «Пешком, скорее всего, будет быстрее». То есть более дорогая версия тоже не удержала физическую суть задачи.
Вердикт: Высокая вычислительная глубина не спасла от логической ошибки.
Ответ ChatGPT 5.4 Pro: модель подробно считает время, но всё равно приходит к неверному выводу, будто пеший сценарий быстрее, хотя без машины задача вообще не выполняется.
Если используете тяжелые модели ChatGPT, сложные аналитические задачи лучше запускать в непиковые часы нагрузки (обычно поздний вечер или ночь по времени США). В периоды высокой нагрузки балансировщики OpenAI могут снижать глубину цепочки рассуждений.
В ролике основной акцент был на Gemini и ChatGPT, а на этой странице отдельно разобраны Claude 4.6 и DeepSeek. Это помогает не терять важные сравнения, которые не вошли в YouTube-версию из-за тайминга.
Обе версии без режима размышления ушли в сухие вычисления скорости и потеряли исходный смысл задачи. То есть проблема была не в арифметике, а в том, что модель переставала держать цель действия.
Быстро идентифицировал логическую ловушку и назвал выбор «машина или пешком» ложной дилеммой: без инструмента (авто) цель недостижима. То есть модель сразу вернула рассуждение в рамку целевого действия, а не в рамку абстрактного сравнения скоростей. По качеству ответа Sonnet 4.6 здесь был уже на уровне Opus 4.6. Сам Opus, ожидаемо, тоже спокойно справился с этой задачей, и тут это не сюрприз: всё-таки речь про одну из самых дорогих моделей на рынке.
Вердикт: Системное мышление у Claude заметно усилилось, а Sonnet 4.6 в таких задачах уже держится на очень высоком уровне.
Последовательно деконструировал задачу: посчитал время движения (~18 секунд), учел амортизационные риски и влияние холодных пусков на двигатель. Финальный вывод: пеший сценарий добавляет лишнее холостое время (порядка нескольких минут); рациональнее ехать на машине.
Вердикт: Практичная логика с учетом эксплуатационных факторов.
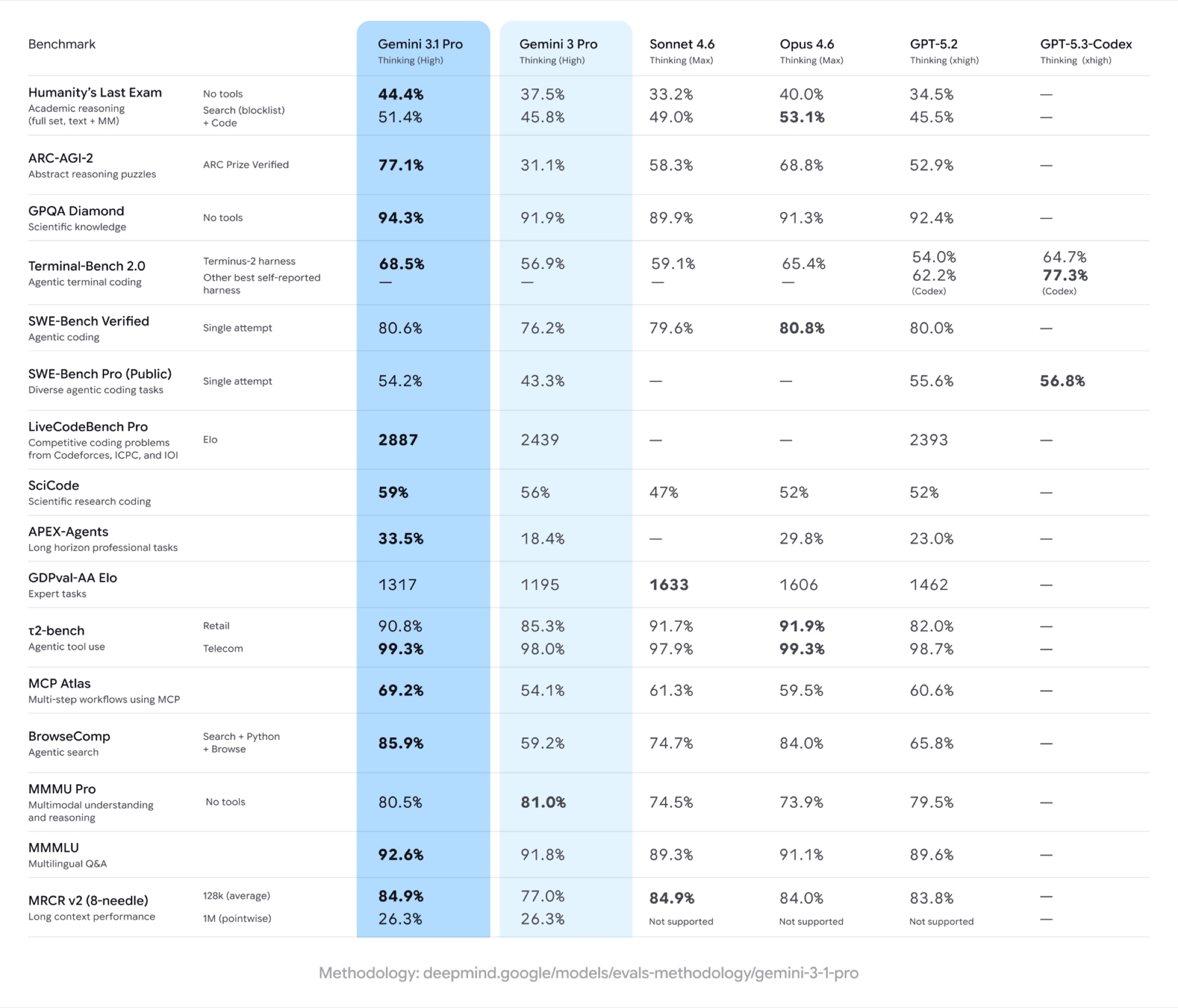
Если вынести личные впечатления за скобки, картину подтверждают и внешние замеры. В ARC-AGI-2 у Gemini зафиксирован результат 77.1%, тогда как у OpenAI — 52.9%. Для этого кейса это важный маркер: лидерство Google в пространственной и причинно-следственной логике подтверждается не только нашим тестом.
График показывает тот же вывод, что и наш тест: в задачах на логику и пространственное мышление Gemini сейчас выглядит заметно сильнее OpenAI.
| Модель | Вход | Выход |
|---|---|---|
| Gemini 3.1 Flash | 21,94 ₽ | 131,67 ₽ |
| DeepSeek V3.2 | 43,89 ₽ | 131,67 ₽ |
| Claude Haiku 4.5 | 87,78 ₽ | 438,89 ₽ |
| Gemini 3.1 Pro | 175,56 ₽ | 1053,33 ₽ |
| GPT-5.4 | 219,44 ₽ | 1316,67 ₽ |
| Claude Sonnet 4.6 | 263,33 ₽ | 1316,67 ₽ |
| GPT-5.4 Pro | 2633,33 ₽ | 15799,99 ₽ |
Важно: Для 90% автоматизаций Gemini 3.1 Flash сейчас выглядит самым сильным кандидатом по соотношению логики и цены. Но если появляется модель лучше и при этом дешевле или бесплатна для вашего сценария, спокойно тестируйте и выбирайте её.
Базовая логика Gemini Flash обходится примерно в 10 раз дешевле стандартной GPT-5.4 и примерно в 120 раз дешевле GPT-5.4 Pro, которая в этом тесте не справилась с задачей пространственного мышления. Для генерации кода OpenAI остается сильным инструментом, но для логики сложных бизнес-процессов лидерство в этом кейсе удерживают Gemini и новые версии Claude.
Если вы строите агентов и автоматизации, выбирайте модель не по маркетингу, а по двум метрикам: устойчивость логики в физическом мире + стоимость токена на масштабе.
Это глубокая, но все же точечная проверка на одном сценарии. Перед внедрением в прод проверяйте модели на своих реальных задачах: поддержка, контент, код, аналитика и автоматизации.
Здесь проверяем популярный миф: действительно ли модель умеет определять локацию только по метаданным или явным подсказкам в кадре. Тест показывает, что сильная мультимодальная модель может работать и тогда, когда таких подсказок почти нет.
Сначала ручная валидация, потом частичная автоматизация. Это самый безопасный порядок внедрения.
Gemini 3.1 Pro определил локацию и направление камеры по «обычному» городскому кадру без метаданных. Ключевой фактор — не поиск картинки в базе, а пространственная геометрия и согласование объектов в сцене.
Мы провели практическую проверку мультимодальности: взяли скриншот неприметной московской улицы, удалили геометки и исключили явные ориентиры. Цель — понять, способна ли модель локализовать точку съемки по структуре пространства.
Дано: серый забор, асфальт, дорожная разметка, несколько зданий на горизонте. Без EXIF, без читаемых вывесок, без «сильных» ориентиров вроде Кремля или Москва-Сити.
Где я? (к сообщению прикреплен скриншот без метаданных)
Исходное изображение: минимум зацепок, только геометрия и горизонт.
Разбор лога показал, что модель использовала последовательную пространственную логику, а не простой поиск похожей картинки.
Модель анализирует дорожную разметку, тип застройки и элементы городской инфраструктуры. В логах возникла промежуточная гипотеза «Санкт-Петербург», но после сверки по освещению и конфигурации улицы модель закрепилась на Москве.
Вердикт: Гипотеза не фиксируется преждевременно: идет поэтапная верификация.
Объект, который базовый CV-классификатор определил бы как «серая стена», модель интерпретировала как шумозащитный экран рядом с железнодорожной инфраструктурой. Это резко сузило область поиска до улиц, идущих параллельно путям.
Вердикт: Ключевая ценность — не лейбл объекта, а его функциональная роль в среде.
Модель сопоставила объекты на горизонте (включая бизнес-центры) и выявила конфликт между текущей гипотезой и фактическим направлением взгляда. После обнаружения несоответствия сценарий был пересчитан, а не «дотянут» до удобного ответа.
Вердикт: Сильная сторона — способность отбрасывать собственную неверную гипотезу.
Финальная локализация строилась через пространственные векторы: направление дорог, взаимное расположение ориентиров и предполагаемый азимут камеры. На выходе модель вычислила конкретный участок улицы и направление обзора.
Вердикт: По сути это геометрическая оценка сцены, а не угадывание по шаблонам.
Pinpointing the Location
I've determined the request involves a street view; the challenge lies in image analysis.
Identifying the Region
I've narrowed down the location to a major street in Moscow or similar city, considering buildings and Russian road signage.
Refining the Hypothesis
I'm now focusing on Elektrozavodskaya Ulitsa, considering the large brick building, grey sound barrier, and red tower possibilities nearby.
Exploring Further Leads
I'm now investigating "Ulitsa Skladochnaya," TTK near Tulskaya and Avtozavodskaya, based on visual clues.
Analyzing the Architecture
I've realized Savelovsky City might be in view, prompting a detailed investigation of Bumazhnyy Proyezd and Skladochnaya Ulitsa.
Reconsidering the Location
I've changed focus to consider Bogorodsky, or even St. Petersburg to account for Russian plates and architecture.
Analyzing the Visual Clues
I've zeroed in on the grey noise barrier, suggesting a railway line like MCC or MCD.
Identifying the Landmark
I think I've confirmed a location near Bumazhnyy Proezd with the Stone Savelovskaya and Alekseevskaya railway, reversing initial hypotheses.
Refining the Hypothesis
I've shifted focus to Ulitsa Sushchevsky Val but dismissed it, instead, considered the ZIL factory area and Avtozavodskaya Ulitsa, also dismissing these.
Narrowing the Location
I've homed in on the Savelovsky City complex and the red tower, and am now looking at Bumazhnyy Proezd or Ulitsa Pravdy.
Confirming the Street
I am now confident that I am on Bumazhnyy Proezd, with the Stone Towers complex to the left.
Pinpointing the Railway
I've determined the grey fence definitely indicates an MCD/railway line near the location.
Exploring Alternative Streets
I am now looking at Ulitsa Nizhnyaya Maslovka and Polkovaya ulitsa, after checking Bumazhnyy Proezd.
Revisiting Location Assumptions
I've reevaluated potential streets like Skladochnaya and Sushchevsky Val based on the red tower's position.
Verifying the Location
I've determined that Presnensky Val, looking east with the railway on the left, could be the right location.
Refining the Location
I'm now investigating Bumazhnyy Proezd with the Stone Towers, and evaluating the view from the street with the railway.
Pinpointing Visual Features
I am now focusing on geometric road features for precise location analysis, particularly lane markings.
Resolving Contradictions
My reasoning identified a key contradiction regarding the view's direction, demanding further refinement to align observations.
Identifying Location Solutions
I am now thoroughly examining several street options, zeroing in on those east of the railway and considering the MCD-4 line.
Confirming Background Features
The background analysis successfully matches the image to Savelovsky City, significantly narrowing the location possibilities.
Verifying Road Perspective
I've confirmed the road's perspective, placing the railway definitively on the right when facing north, using directional markings.
Refining Location Details
I have now confirmed Bolshaya Novodmitrovskaya as a potential starting point, analyzing the perspective.
Revisiting Building Options
I've shifted focus to skyscraper possibilities like "D1" near Dmitrovskaya, as well as several old factory options.
Confirming Perspective Alignment
I have now definitively placed Savelovsky City to the right, confirming the MCD-1 railway's location to the left.
Confirming Directional Perspective
I've finally pinpointed the correct directional view, concluding Butyrskiy Val, looking North-East, aligns perfectly.
Confirming Visual Alignment
I have now perfectly placed Stone Towers, a long brick building, and Savelovsky City within the scene.
Verifying Precise Location
My analysis now confirms Butyrskiy Val, pinpointing Butyrskiy Val 68 as the key location with Stone Towers visible.
Refining Visual Distances
I am now resolving directional inconsistencies concerning Savelovsky City and Stone Towers, analyzing azimuth.
Calculating Azimuth Angles
My analysis now confirms Stone Towers and Savelovsky City's positions relative to Butyrskiy Val, validating the image.
Validating Street Details
I have now confirmed Butyrskiy Val 68 and Baker Plaza's alignment, refining the exact photo viewpoint.
Confirming Detailed View
My analysis confirms the Butyrskiy Val view; Stone Towers, Savelovsky City, and railway alignment are precise.
Confirming Viewpoint Features
I have precisely confirmed every visual feature, definitively matching the scene's objects for an exact location solution.
Finalizing Response Details
The analysis confirms the optimal format for the answer, including the Russian and English breakdown, with street details.
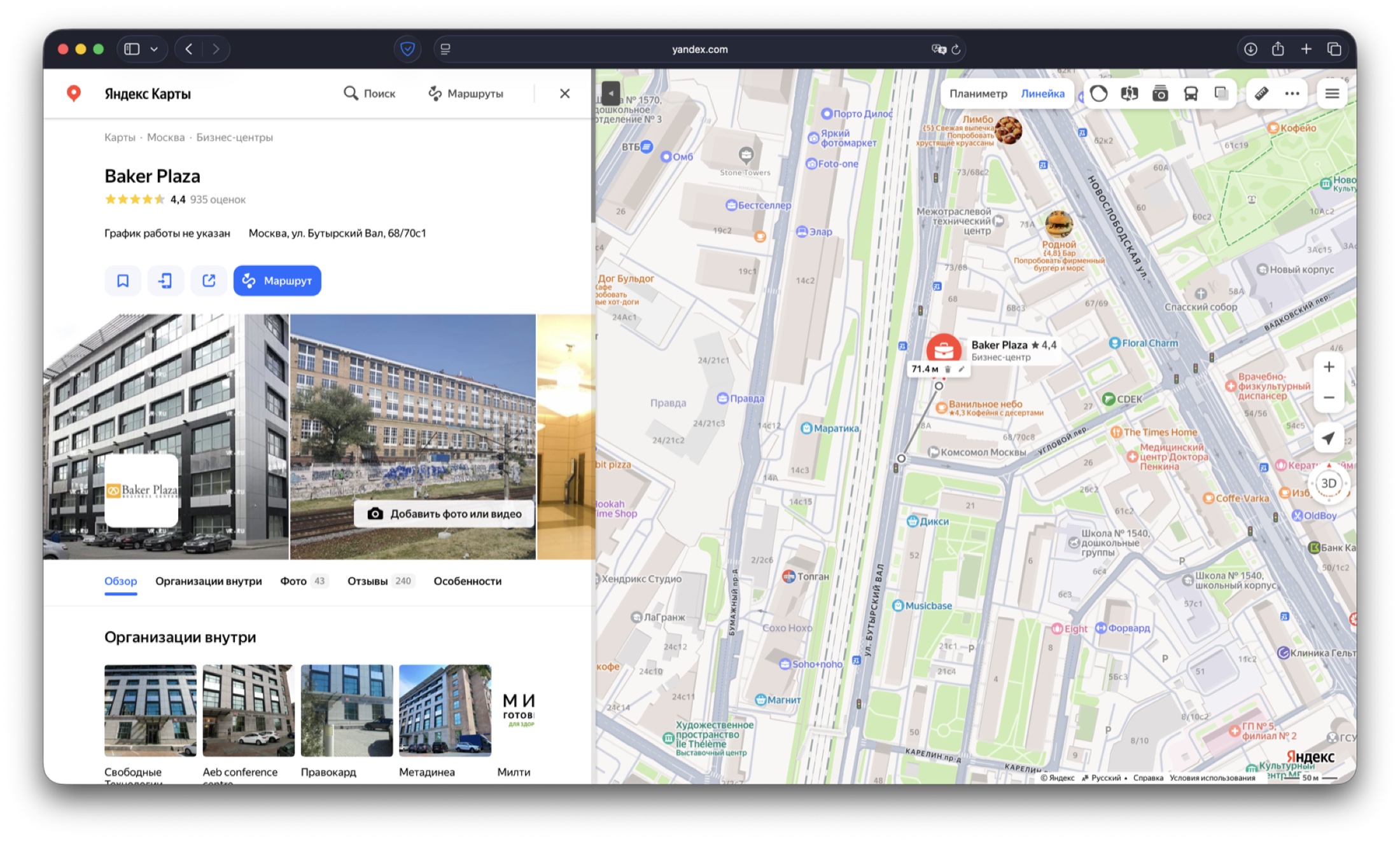
Ответ Gemini: Москва, улица Бутырский Вал, направление камеры — северо-восток. По факту модель ошиблась буквально на один перекресток, но Baker Plaza оказалась совсем рядом, а дальше по сцене виден и Савеловский City. Для такого нейтрального кадра это всё равно очень сильное попадание по локации и азимуту.
Результат: точное попадание в координаты. ИИ нашел точку на Бутырском Валу.
Это единичная, но глубокая проверка. Перед внедрением в производственный контур модель необходимо прогнать на вашей географии, ваших типах камер и ваших сценариях ошибок.
В этом тесте Gemini 3.1 Pro показал, что современная мультимодальная модель может работать с пространственной логикой на уровне прикладной геометрии сцены. Для бизнеса это означает переход от «распознавания картинки» к анализу реального физического контекста.
После статичных тестов переходим к движению. Здесь важно понять, способен ли ИИ не просто выдать общий совет, а разобрать реальную технику по видео и подсказать корректировки, которые можно проверить уже на следующей тренировке.
Маленькие проверяемые корректировки почти всегда полезнее, чем резкая полная перестройка.
ИИ показал высокую полезность в разборе биомеханики (углы, траектория, стартовое натяжение), но не заменяет тренера и не должен использоваться как единственный источник решений по нагрузке и здоровью.
Тест строился на реальном подходе с рабочим весом 180 кг. Задача была намеренно прикладной: проверить, насколько рекомендации модели помогают убрать грубые технические ошибки и улучшить качество выполнения уже на следующей тренировке.
Проанализируй мою становую тягу и найди ошибки. В основном я тяну в классике, но тут решил потянуть в сумо. (к сообщению прикреплено видео подхода 180 кг)
180 кг: гриф 20 кг ZIVA + 8 дисков по 15 кг + 2 диска по 20 кг.
На этапе компьютерного зрения модель ошиблась в оценке веса на штанге: вместо 180 кг определила 210 кг. Этот эпизод важно учитывать как ограничение CV-модуля при работе с перекрывающимися объектами в 2D-кадре.
После визуальной ошибки в оценке веса модель при этом дала содержательный и точный разбор биомеханики самого движения.
Таз находился слишком далеко от грифа, из-за чего корпус избыточно заваливался вперед. Для сумо-стиля это критично: движение начинает походить на «очень широкую классику» и теряет рычажные преимущества.
Вердикт: Коррекция: подвести таз ближе к грифу и выстроить старт так, чтобы сохранить вертикаль усилия.
В момент срыва штанга уходила вперед от голени, что смещало центр тяжести и ухудшало механику движения.
Вердикт: Коррекция: удерживать гриф ближе к телу на старте и контролировать вертикальную траекторию.
Перед началом подъема не хватало нормальной натяжки штанги и мышц: вместо собранного старта получался резкий рывок. Для сумо это снижает стабильность в самой важной фазе движения и ухудшает передачу усилия с пола.
Вердикт: Коррекция: перед отрывом штанги сформировать жесткое натяжение системы «тело-гриф-пол».
Практическая проверка была сделана уже на следующий день, примерно через 20 часов после первого подхода. За такой промежуток времени я сильнее, конечно, не стал — скорее наоборот, был более уставшим. Это важно, потому что повторное видео с 200 кг — реальное, не ИИ-сгенерированное: никого в заблуждение я здесь не ввожу. Акцент был только на корректировках из разбора — позиция таза, траектория и стартовое натяжение. Дополнительный контекст: подход выполнялся без жесткого силового пояса.
200 кг: гриф 20 кг ZIVA + 12 дисков по 15 кг.
За сутки физическая сила не меняется существенно, но за счет коррекции биомеханики 200 кг на 2 повторения, то есть +20 кг к предыдущему тесту, ощущались стабильнее и субъективно легче, чем подход 180 кг с ошибками техники.
Компетентный живой тренер остается приоритетом. ИИ стоит использовать как вспомогательный аналитический слой, особенно при отсутствии тренера, но не как основу для самостоятельного построения макроциклов и работы через боль.
Кейс подтвердил практическую роль ИИ как прикладного аналитика: модель способна выявлять критические дефекты техники и давать корректировки, которые можно проверить в следующей итерации. Ключ к качеству результата — валидный видеовход, контроль рисков и обязательная человеческая экспертиза.
В этом кейсе ИИ выступает не как генератор красивых картинок, а как строгий критик идеи и помощник в сборке MVP. Сначала он разбирает слабую гипотезу, потом помогает быстро собрать более жизнеспособный вариант запуска.
Чем раньше вы разрешите ИИ критиковать гипотезу, тем дешевле будет ошибка.
На старте ИИ дал не «поддерживающий», а критически полезный разбор концепции и предложил более жизнеспособную архитектуру запуска: Dark Kitchen + Telegram-бот + агрегаторы доставки.
Исходная гипотеза: премиум-суши «Сакура» в спальном районе Москвы со средним чеком 3000 ₽ и собственной доставкой. Цель — выявить слабые места и найти реалистичный сценарий запуска с минимальным временем и бюджетом.
Идея: открыть суши-бар «Сакура» в спальном районе Москвы, только премиум-роллы, средний чек 3000 ₽, выдача и своя доставка. Найди слабые места и предложи более жизнеспособный бюджетный запуск.
Модель отработала как прагматичный аналитик и декомпозировала риск по ключевым бизнес-блокам.
Для выбранной территории премиальное позиционирование в исходном виде выглядело рискованно: высокий чек не поддерживался контекстом района и операционной моделью.
Вердикт: Коррекция: пересобрать формат запуска, а не усиливать маркетинг на слабом фундаменте.
Название «Сакура» модель оценила как перегруженное ассоциациями массового сегмента и недостаточно выразительное для премиальной упаковки.
Вердикт: Коррекция: ребрендинг в более чистую визуально-лексическую систему (KURO).
Собственная курьерская логистика в нулевой фазе формирует избыточные фиксированные расходы и операционный риск.
Вердикт: Коррекция: вынести доставку в агрегаторы до достижения устойчивого объема.
ИИ предложил формат Dark Kitchen, жесткое позиционирование в азиатский минимализм (KURO), прием заказов через Telegram-бот и интеграции автоматизации через n8n.
Вердикт: Фокус на экономике запуска и скорости проверки гипотез.
Отдельно интересно, что модель предложила Telegram-бот не в вакууме. Она опиралась на контекст прошлых задач и твой бэкграунд с ботами и автоматизациями на n8n, поэтому решение получилось не абстрактным, а привязанным к реальному стеку и сильным сторонам.
Логотип KURO и первый фирменный носитель: уже здесь видно, как бренд собирается в чистую минималистичную систему.
Черная матовая коробка на темном камне: фирменная упаковка, которая сразу задает премиальный тон.
Эти промпты отвечают за первую визуальную систему бренда: знак, упаковку и базовый арт-дирекшн.
Создай минималистичный логотип для премиального суши-бренда KURO. Белый фон, глубокий черный знак, чистая типографика, ощущение японского минимализма без лишнего декора.
Черная матовая коробка для премиального суши-бренда KURO лежит на темном камне. Мягкий направленный свет, дорогая текстура, логотип читается четко, кадр выглядит как luxury food branding.
Первый food-визуал для меню KURO: премиальная подача, тёмный фон и аккуратная композиция без лишнего шума.
Запеченные роллы «Вулкан» как отдельный hero-кадр для меню и промо-материалов.
Сравнение до и после показывает, как аккуратная правка в диалоге помогает удержать нужную конструкцию ролла и довести кадр до более премиальной подачи.
Эти промпты уже не про бренд в целом, а про конкретные артефакты меню и контроль композиции в кадре.
Премиальная подача роллов «Филадельфия», ровно 8 штук, ракурс 45 градусов, мягкий студийный свет, черный фон, глубокие текстуры лосося, кадр как для high-end food campaign.
Запеченный ролл «Вулкан» крупным планом, теплая фактура, запеченная шапка, выразительный блеск, темный фон, высокая детализация, premium food photography.
Я обычным языком попросил обернуть ролл в нори. С первого раза получилось именно то, что было нужно.
Практический вывод: держите контекст чистым и не захламляйте чат лишними сообщениями. Если результат уходит не туда, проще быстро перегенерировать, чем тащить за собой старый шум.
Короткий ролик, где японский шеф-повар приветствует зрителя и задает тон бренду.
Макросъемка разрезания лосося для промо-кадров, сторис и рекламных креативов.
Крупный план разрезания суши как отдельный food-shot для роликов и рекламных вставок.
Интро, в котором логотип будто выжигается на камне: сильный визуальный финал для всего кейса.
Здесь уже подключаются VEO 3.1 и Flow: приветствие шефа, отдельные food-shot ролики и финальная анимация логотипа.
Японский шеф-повар стоит в темной премиальной кухне и коротко приветствует зрителя. Кинематографичный свет, медленное движение камеры, премиальный тон, ощущение бренда luxury delivery.
Макросъемка, слоу-моушен 120 кадров в секунду, 4K, острый стальной нож плавно разрезает свежий сырой лосось. Глубокий черный фон, высокая детализация, премиальный food-shot.
Крупный план, slow motion, 4K: аккуратный нож разрезает суши на темном фоне. Чистый кадр, мягкий кинематографичный свет, акцент на текстуре и точности движения.
Логотип KURO медленно проявляется на темном камне как будто выжигается жаром. Легкий дым, угольное свечение, минималистичный кадр, финал как у премиального бренд-интро.
Gemini и VEO сейчас действительно выглядят как очень сильные инструменты для видео, но рынок меняется быстро. Китайские модели часто выходят дешевле и нередко дают результат не хуже, а иногда и лучше в отдельных задачах. Поэтому здесь главный вывод не в том, что есть одна «лучшая» модель, а в том, что под свою нишу и формат роликов стоит регулярно тестировать несколько вариантов.
За один рабочий цикл была собрана цельная MVP-концепция: бизнес-модель, позиционирование, фирменная упаковка и базовый набор визуального контента для запуска и теста спроса.
Кейс подтвердил, что ИИ способен закрывать не только креативные задачи, но и ранний продуктовый консалтинг: выявление рисков, пересборка модели и ускорение вывода MVP в рынок.
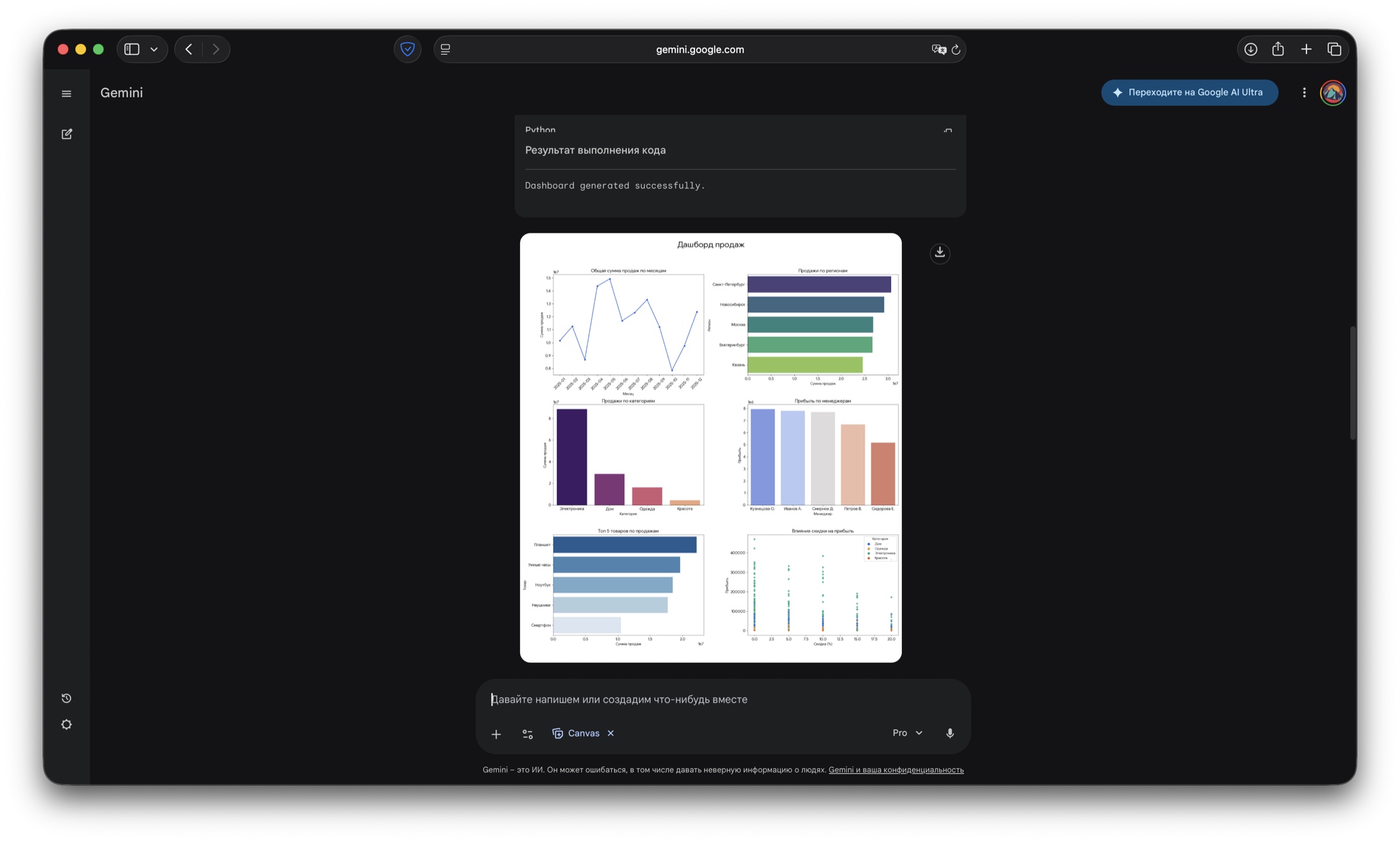
Этот кейс отвечает на очень практичный вопрос: можно ли взять обычный CSV-файл и быстро превратить его в рабочий интерфейс аналитики, а не в еще один статичный отчет.
Сначала полезность для решения, потом красота дашборда. Иначе получится витрина, а не инструмент.
Модель справилась с двумя уровнями задачи: сначала собрала базовый аналитический слой в песочнице Python, затем развернула интерактивный интерфейс, который можно передавать команде по ссылке.
Для теста использовался CSV на 1000 строк с продажами, городами и менеджерами. Проверка фокусировалась на скорости перехода от файла к прикладной аналитике: фильтры, визуализации, итеративные правки и публикация.
Проанализируй этот CSV-файл с продажами и собери удобный аналитический интерфейс: фильтры по городам/категориям/менеджерам, ключевые графики и возможность быстро добавлять новые расчетные метрики.
Модель автоматически написала и выполнила код во встроенном Python-режиме, построив первичные срезы и графики. Это дало быструю опорную картину для проверки структуры и качества данных.
Вердикт: Подходит для оперативного первичного анализа и диагностики датасета.
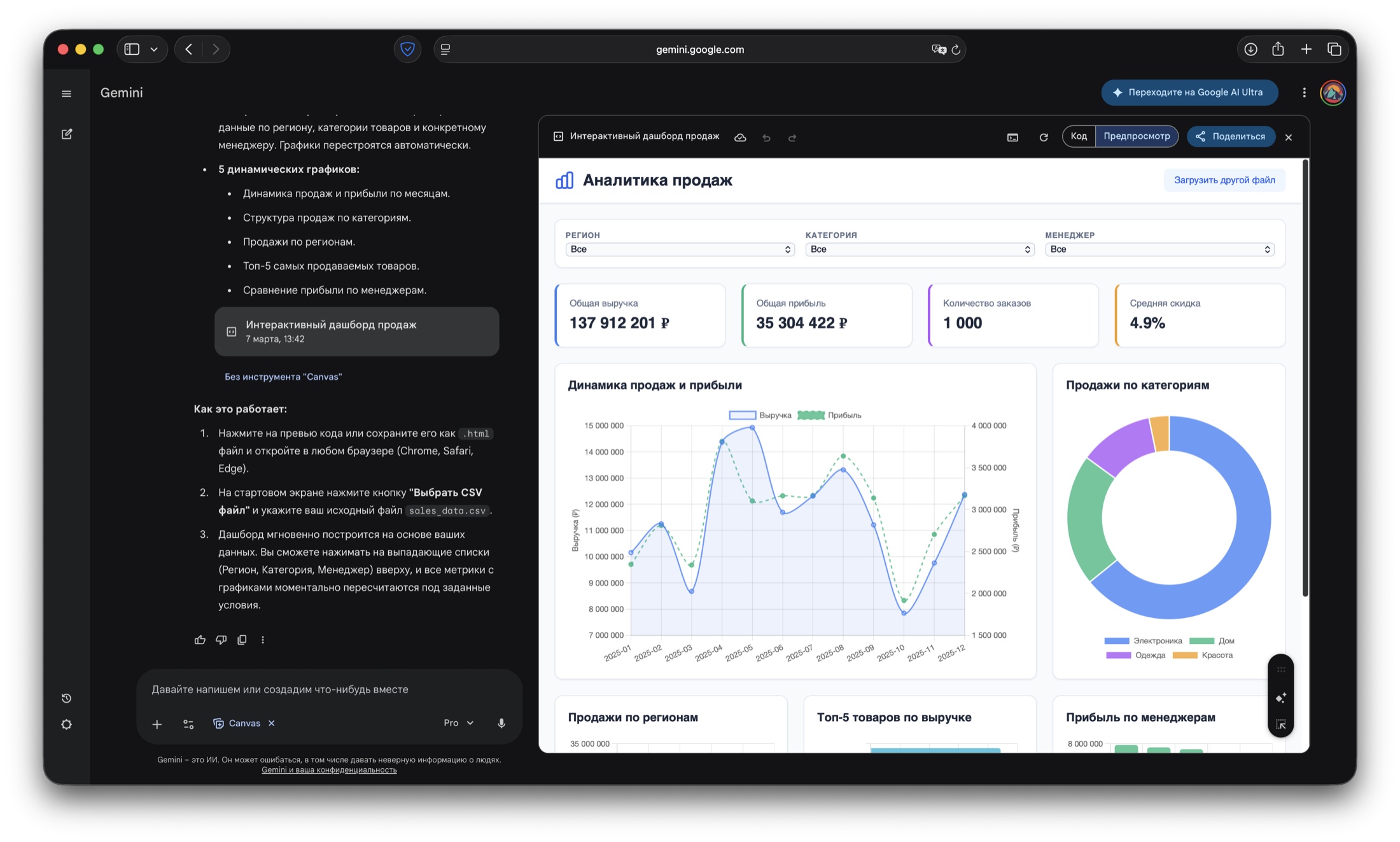
Следующий этап — генерация интерактивного интерфейса: фильтры, обновляемые графики, быстрые правки логики расчетов без ручной пересборки проекта.
Вердикт: Переход от статичного отчета к рабочему продукту для команды.
Интерфейс можно развернуть и отдать коллегам ссылкой. Дополнительные формулы и метрики внедряются через промпт и сразу отражаются в UI.
Вердикт: Ускорение цикла «вопрос бизнеса → рабочий инструмент анализа».
Первый шаг: модель сама разобрала CSV, собрала первичные графики и показала, что именно происходит в данных до сборки интерфейса.
Следующий шаг: из того же датасета модель собрала уже не просто отчет, а живой интерфейс с фильтрами, KPI и графиками для командной работы.
Качество результата напрямую зависит от качества входных данных и корректности бизнес-логики метрик. Финальные управленческие решения требуют валидации аналитиком и владельцем процесса.
ИИ показал, что может закрывать полный прикладной цикл аналитики: от обработки CSV до интерактивного инструмента, пригодного для ежедневной командной работы.
Здесь проверяем связку “разобрал -> предложил -> внедрил”. То есть может ли ИИ сначала провести внятный аудит интерфейса, а потом помочь довести замечания до реальных изменений в коде.
Быстрее всего растет не тот продукт, где "поправили все", а тот, где улучшили один критичный путь.
При корректной постановке роли и входных данных модель формирует качественный UX-аудит, а связка с агентом позволяет перейти от замечаний к конкретным коммитам и Pull Request.
Объект теста — закрытый продукт в разработке: база знаний, видеоразборы и материалы для сообщества. Задача: выявить узкие места интерфейса и проверить возможность их автоматизированного исправления.
Выступи как Senior UX/UI reviewer. Проанализируй экранные блоки продукта и дай приоритетный список улучшений по контрасту, иерархии CTA, читаемости и логике пользовательского сценария.
Выявлены зоны слабого контраста: часть текста терялась на темном фоне, что снижало читаемость на мобильных экранах.
Вердикт: Коррекция: усиление контраста и выравнивание типографической иерархии.
Обнаружены конфликты в иерархии целевых действий: несколько CTA конкурировали между собой и размывали основной сценарий.
Вердикт: Коррекция: переразметка приоритетов и упрощение пути до целевого действия.
Проверка календарных и контентных блоков показала несогласованности в последовательности пользовательского пути.
Вердикт: Коррекция: синхронизация логики экранов и контентных переходов.
Текст аудита был передан автономному ИИ-агенту, который внес изменения в кодовую базу, обновил компоненты и стили, а затем сформировал Pull Request с описанием внесенных правок.
Визуальная разница после аудита: чище иерархия, лучше читаемость, понятнее CTA и более собранный пользовательский путь.
Живой проход по обновлённому сайту после аудита и внедрения правок: видно не только статичные экраны, но и общее ощущение от интерфейса в движении.
Автономная правка кода требует обязательного human-review перед релизом. ИИ ускоряет цикл, но ответственность за продуктовые решения и регрессионную проверку остается на команде.
Кейс показал рабочую связку «аудит + исполнение»: ИИ может не только обнаруживать UX-проблемы, но и участвовать в их техническом устранении до уровня готового PR.
Финальный кейс про работу с большими документами: не просто быстро пересказать отчет, а достать из него структуру решений, заметить противоречия и собрать понятный краткий бриф для команды.
Главная ценность не в пересказе, а в том, что модель помогает быстрее замечать смысловые конфликты.
NotebookLM показал высокую эффективность в систематизации больших документов: выделение ключевых тезисов, генерация представления для команды и обнаружение внутренних логических противоречий.
В тест загружались два крупных PDF-отчета по внедрению ИИ-агентов в бизнесе. Цель — оценить не только скорость извлечения тезисов, но и способность модели критически проверять связность источников.
Проанализируй загруженные отчеты, выдели ключевые драйверы внедрения ИИ, собери краткую структуру для презентации и отметь внутренние противоречия в аргументации источников.
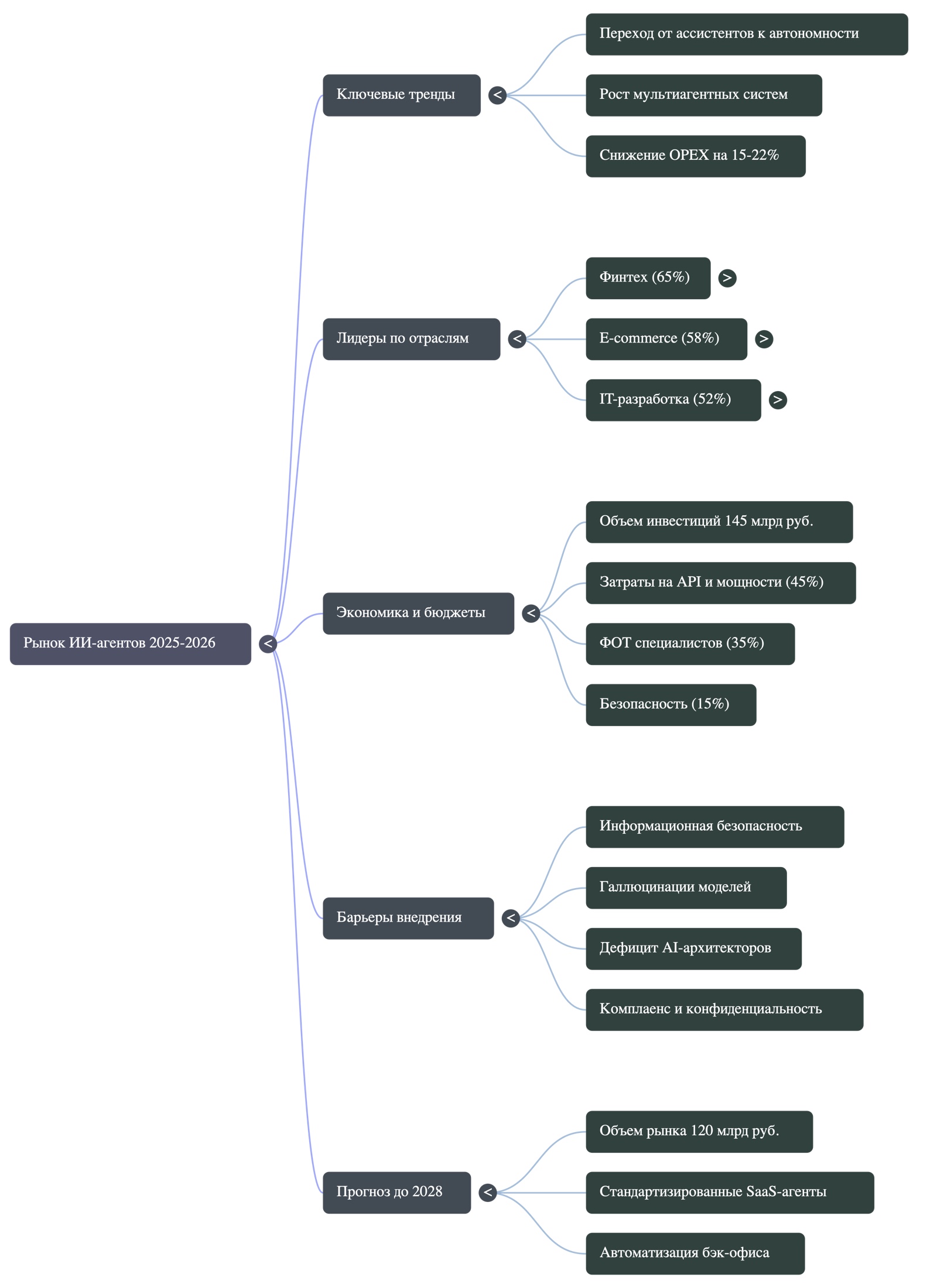
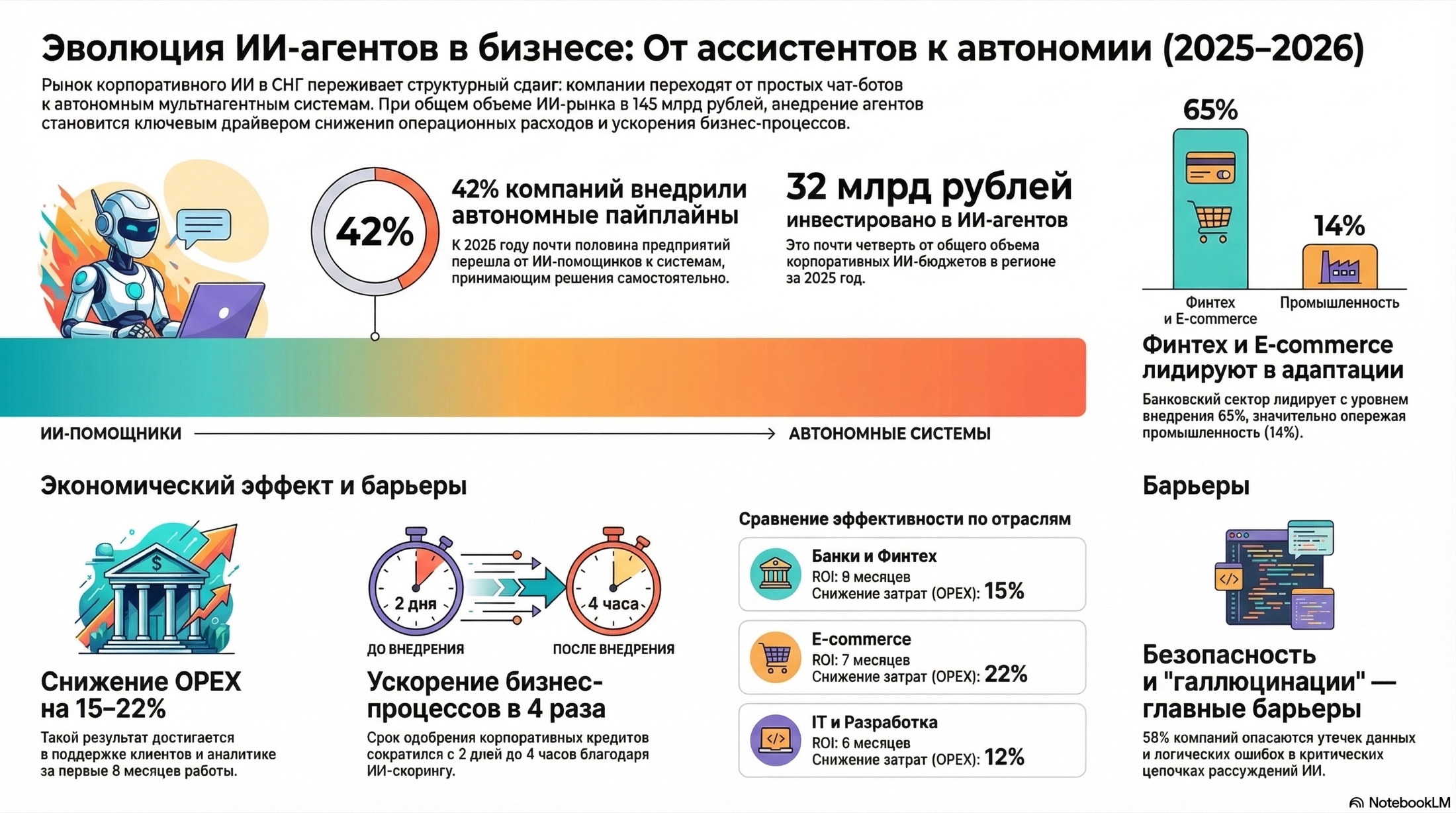
Система собрала ментальные карты и инфографические тезисы: тренды, барьеры, экономические эффекты и ключевые цифры для управленческой коммуникации.
Вердикт: Сильная скорость перехода от «сырого документа» к рабочей структуре.
В аудиоформате были обнаружены логические несостыковки между текстом и таблицами (разные «главные драйверы» на уровне тезисов и фактических данных).
Вердикт: ИИ используется не только для пересказа, но и для критического контроля источника.
При обнаружении устаревшего блока в слайде модель получила короткую правку и пересобрала содержание с учетом актуального контекста и новой версии инструментов.
Вердикт: Высокая скорость корректировок без ручной переработки всей презентации.
Визуальная выжимка из больших отчетов: ключевые тезисы, цифры и связи, которые можно быстро отдать команде в работу.
Короткий аудиоразбор помогает быстро услышать, где тезисы отчета расходятся с таблицами и фактическими выводами.
На картинке выше вы видите инфографику, которую можно быстро показать команде или использовать как короткий рассказ по теме без длинного пересказа всего отчета.
PDF загружается по запросу, чтобы страница открывалась быстрее на медленных устройствах и сетях.
Здесь можно пролистать всю презентацию прямо на странице: инфографика, структура выводов и обновленные слайды в одном документе.
Открыть PDF в новой вкладкеЛюбые числовые и фактологические выводы, извлеченные ИИ, требуют ручной проверки по первоисточнику. Модель ускоряет аналитический цикл, но не отменяет процедуру валидации.
NotebookLM в этом тесте выступил как аналитический ускоритель: структурирует большие документы, помогает обнаруживать смысловые разрывы и снижает стоимость подготовки качественных управленческих материалов.
Все 7 кейсов уже на странице. Дальше я буду добавлять новые разборы и усиливать существующие кейсы свежими материалами, скриншотами и рабочими примерами.
Если формат полезен, я продолжу выпускать новые кейсы и обновлять текущие разборы, когда появляются сильные примеры и новые материалы.
В Telegram я сначала публикую новые разборы, обновления и короткие практические заметки.
Если хотите предложить тему или улучшить подачу кейсов — напишите в личные сообщения.